BehAV: Behavioral Rule Guided Autonomy Using VLMs for Robot Navigation in Outdoor Scenes
Oct 11, 26260·,,,, ,,·
0 min read
,,·
0 min read
Kasun Weerakoon
Mohamed Elnoor
Gershom Seneviratne
Vignesh Rajagopal
Senthil Hariharan Arul
Jing Liang
Mohamed Khalid M Jaffar
Dinesh Manocha
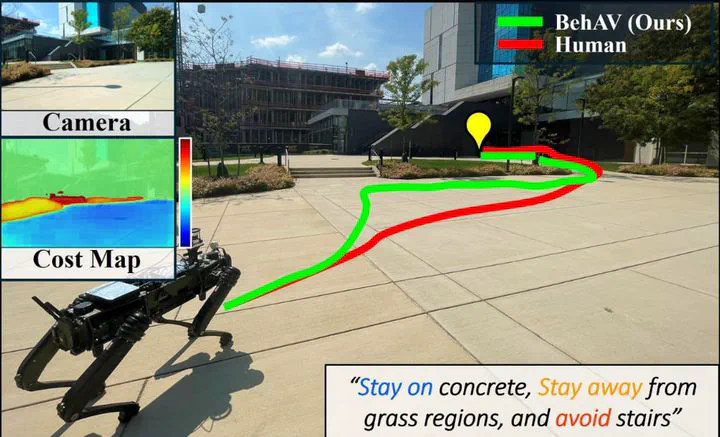 Image credit:
Image credit:Abstract
We present BehAV, a novel approach for autonomous robot navigation in outdoor scenes guided by human instructions and leveraging Vision Language Models (VLMs). Our method interprets human commands using a Large Language Model (LLM), and categorizes the instructions into navigation and behavioral guidelines. Navigation guidelines consist of directional commands (e.g., “move forward until”) and associated landmarks (e.g., “the building with blue windows”), while behavioral guidelines encompass regulatory actions (e.g., “stay on”) and their corresponding objects (e.g., “pavements”). We use VLMs for their zero-shot scene understanding capabilities to estimate landmark locations from RGB images for robot navigation. Further, we introduce a novel scene representation that utilizes VLMs to ground behavioral rules into a behavioral cost map. This cost map encodes the presence of behavioral objects within the scene and assigns costs based on their regulatory actions. The behavioral cost map is integrated with a LiDAR-based occupancy map for navigation. To navigate outdoor scenes while adhering to the instructed behaviors, we present an unconstrained Model Predictive Control (MPC)-based planner that prioritizes both reaching landmarks and following behavioral guidelines. We evaluate the performance of BehAV on a quadruped robot across diverse real-world scenarios, demonstrating a 22.49% improvement in alignment with human-teleoperated actions, as measured by Fréchet distance, and achieving a 40% higher navigation success rate compared to state-of-the-art methods.
Type
Publication
IEEE International Conference on Robotics and Automation (ICRA), 2025