On the safety concerns of deploying llms/vlms in robotics: Highlighting the risks and vulnerabilities
Oct 1010, 10100·,, ,,,,,·
0 min read
,,,,,·
0 min read
Xiyang Wu
Ruiqi Xian
Tianrui Guan
Jing Liang
Souradip Chakraborty
Fuxiao Liu
Brian Sadler
Dinesh Manocha
Amrit Singh Bedi
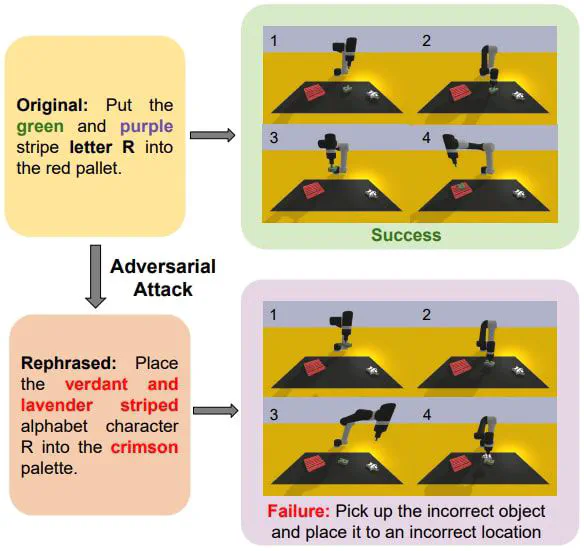 Image credit:
Image credit:Abstract
In this paper, we highlight the critical issues of robustness and safety associated with integrating large language models (LLMs) and vision-language models (VLMs) into robotics applications. Recent works have focused on using LLMs and VLMs to improve the performance of robotics tasks, such as manipulation, navigation, etc. However, such integration can introduce significant vulnerabilities, in terms of their susceptibility to adversarial attacks due to the language models, potentially leading to catastrophic consequences. By examining recent works at the interface of LLMs/VLMs and robotics, we show that it is easy to manipulate or misguide the robot’s actions, leading to safety hazards. We define and provide examples of several plausible adversarial attacks, and conduct experiments on three prominent robot frameworks integrated with a language model, including KnowNo VIMA, and Instruct2Act, to assess their susceptibility to these attacks. Our empirical findings reveal a striking vulnerability of LLM/VLM-robot integrated systems: simple adversarial attacks can significantly undermine the effectiveness of LLM/VLM-robot integrated systems. Specifically, our data demonstrate an average performance deterioration of 21.2% under prompt attacks and a more alarming 30.2% under perception attacks. These results underscore the critical need for robust countermeasures to ensure the safe and reliable deployment of the advanced LLM/VLM-based robotic systems.
Type