MOSU: Autonomous Long-range Robot Navigation with Multi-modal Scene Understanding
Oct 55, 8080· ,,,,,·
0 min read
,,,,,·
0 min read
Jing Liang
AKasun Weerakoon
Daeun Song
Senthurbavan Kirubaharan
Xuesu Xiao
Dinesh Manocha
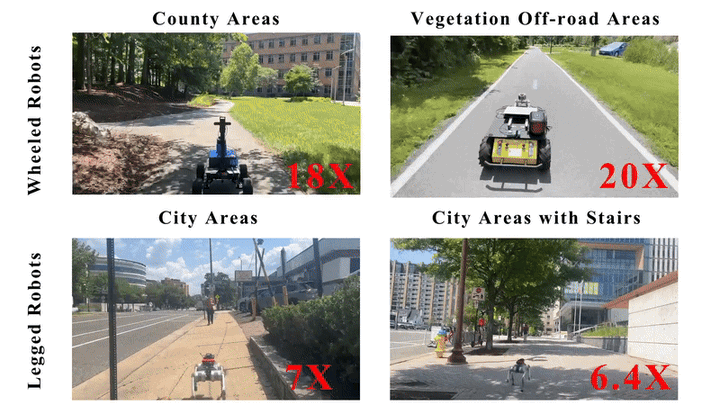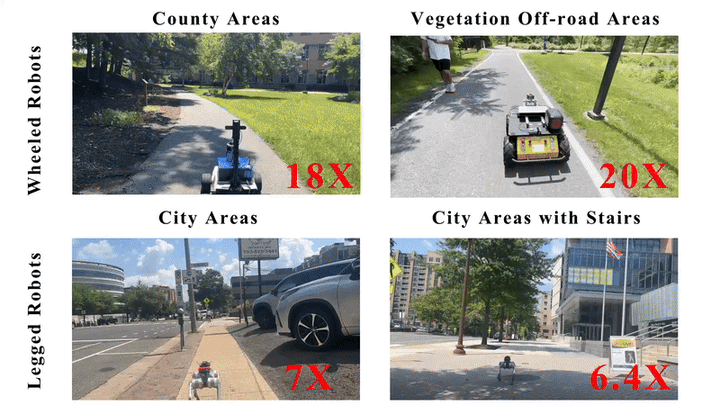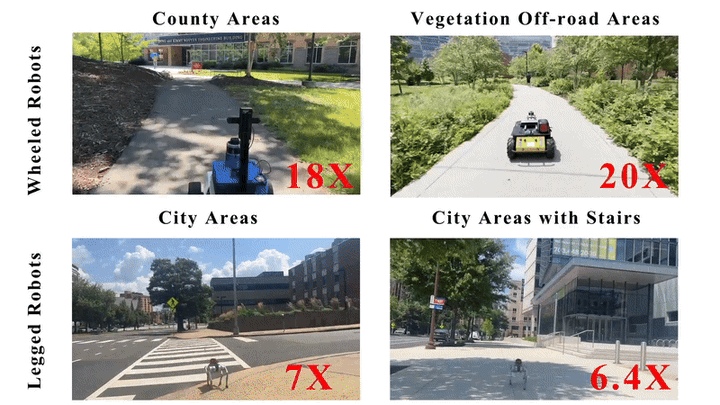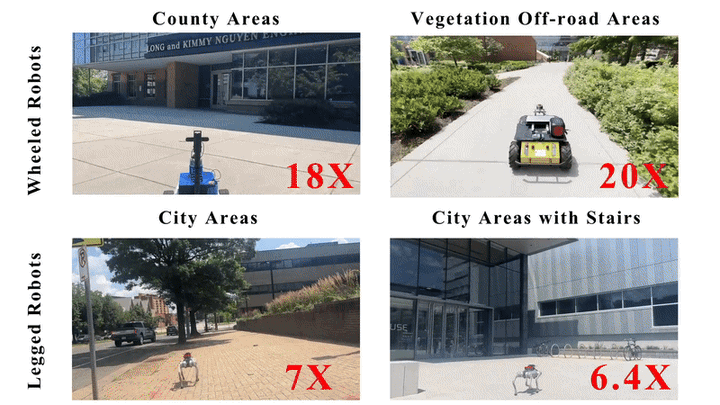 Image credit:
Image credit:Abstract
We present MOSU, a novel autonomous long-range naviga- tion system that enhances global navigation for mobile robots through multimodal perception and on-road scene understanding. MOSU ad- dresses the outdoor robot navigation challenge by integrating geometric, semantic, and contextual information to ensure comprehensive scene un- derstanding. The system combines GPS and QGIS map-based routing for high-level global path planning and multi-modal trajectory genera- tion for local navigation refinement. For trajectory generation, MOSU leverages multi-modalities, including LiDAR-based geometric data for precise obstacle avoidance, image-based semantic segmentation for traversability assessment, and Vision-Language Models (VLMs) to capture social con- text and enable the robot to adhere to social norms in complex environ- ments. This multi-modal integration improves scene understanding and enhances traversability, allowing the robot to adapt to diverse outdoor conditions. We evaluate our system in real-world on-road environments and benchmark it on the GND dataset, achieving a 10% improvement in traversability on navigable terrains while maintaining a comparable navigation distance to existing global navigation methods.
Type
Publication
International Symposium on Experimental Robotics 2025