AutoSpatial: Visual-Language Reasoning for Social Robot Navigation through Efficient Spatial Reasoning Learning
Oct 66, 10100·, ,,,·
0 min read
,,,·
0 min read
Yangzhe Kong
Daeun Song
Jing Liang
Dinesh Manocha
Ziyu Yao
Xuesu Xiao
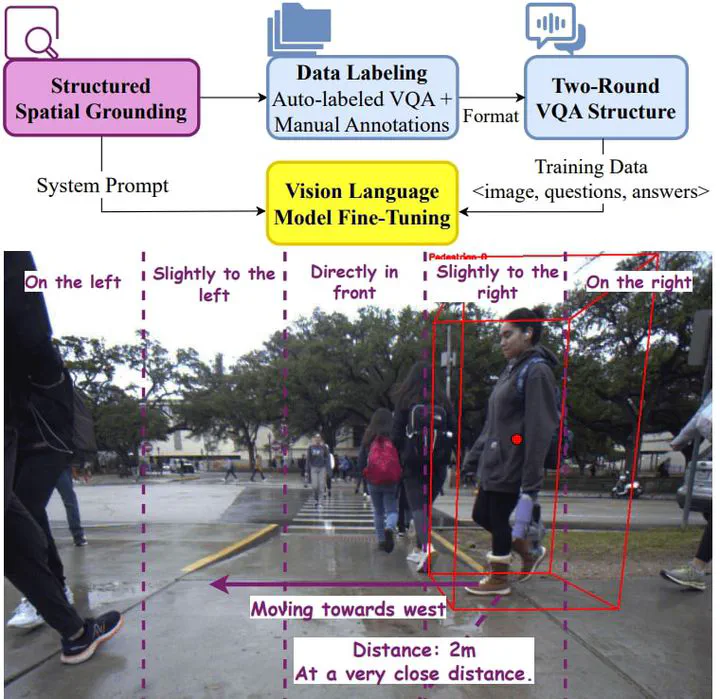 Image credit:
Image credit:Abstract
We present a novel method, AutoSpatial, an efficient approach with structured spatial grounding to enhance VLMs’ spatial reasoning. By combining minimal manual supervision with large-scale Visual Question-Answering (VQA) pairs auto-labeling, our approach tackles the challenge of VLMs’ limited spatial understanding in social navigation tasks. By applying a hierarchical two-round VQA strategy during training, AutoSpatial achieves both global and detailed understanding of scenarios, demonstrating more accurate spatial perception, movement prediction, Chain of Thought (CoT) reasoning, final action, and explanation compared to other SOTA approaches. These five components are essential for comprehensive social navigation reasoning. Our approach was evaluated using both expert systems (GPT-4o, Gemini 2.0 Flash, and Claude 3.5 Sonnet) that provided cross-validation scores and human evaluators who assigned relative rankings to compare model performances across four key aspects. Augmented by the enhanced spatial reasoning capabilities, AutoSpatial demonstrates substantial improvements by averaged cross-validation score from expert systems in perception & prediction (up to 10.71%), reasoning (up to 16.26%), action (up to 20.50%), and explanation (up to 18.73%) compared to baseline models trained only on manually annotated data.
Type
Publication
2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)